Temporal Distillation: Compressing a Policy in Space and Time. Thomas Avé, Matthias Hutsebaut-Buysse, Kevin Mets. Machine Learning, vo. 114, 15 October 2025
https://link.springer.com/article/10.1007/s10994-025-06889-9
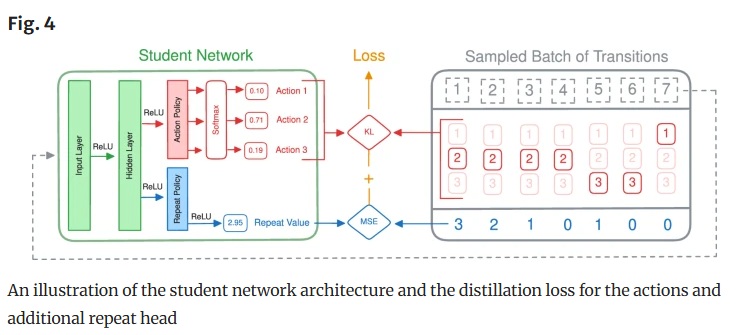
Deploying deep reinforcement learning on resource-constrained devices remains a significant challenge due to the energy-intensive nature of the sequential decision-making process. Model compression can reduce the spatial (e.g. storage, memory) requirements of a policy network, but this does not always translate to a proportional increase in inference speed and computational efficiency. We introduce a novel temporal compression paradigm that improves the efficiency more directly, by reducing the number of predictions needed to complete a task. This method, based on policy distillation, allows a student model to learn when a change of action will be required by observing sequences of identical actions in the trajectories of an existing teacher model. At each decision, the student can then predict both an action and how many times to perform this action consecutively. This approach allows any existing policy for discrete action spaces to be optimized for energy efficiency through both spatial and temporal compression simultaneously. Experiments on devices ranging from a microcontroller and smartphone processor to a data centre GPU show how this method can decrease the average time it takes to predict an action by up to 13.5 times, compared to 4 times through spatial compression alone, while maintaining a similar average return as the original teacher. In practice, this allows complex models to be deployed on ultra-low-power devices, enabling them to conserve energy by remaining in sleep mode for longer periods, and still achieve high runtime and task performance.